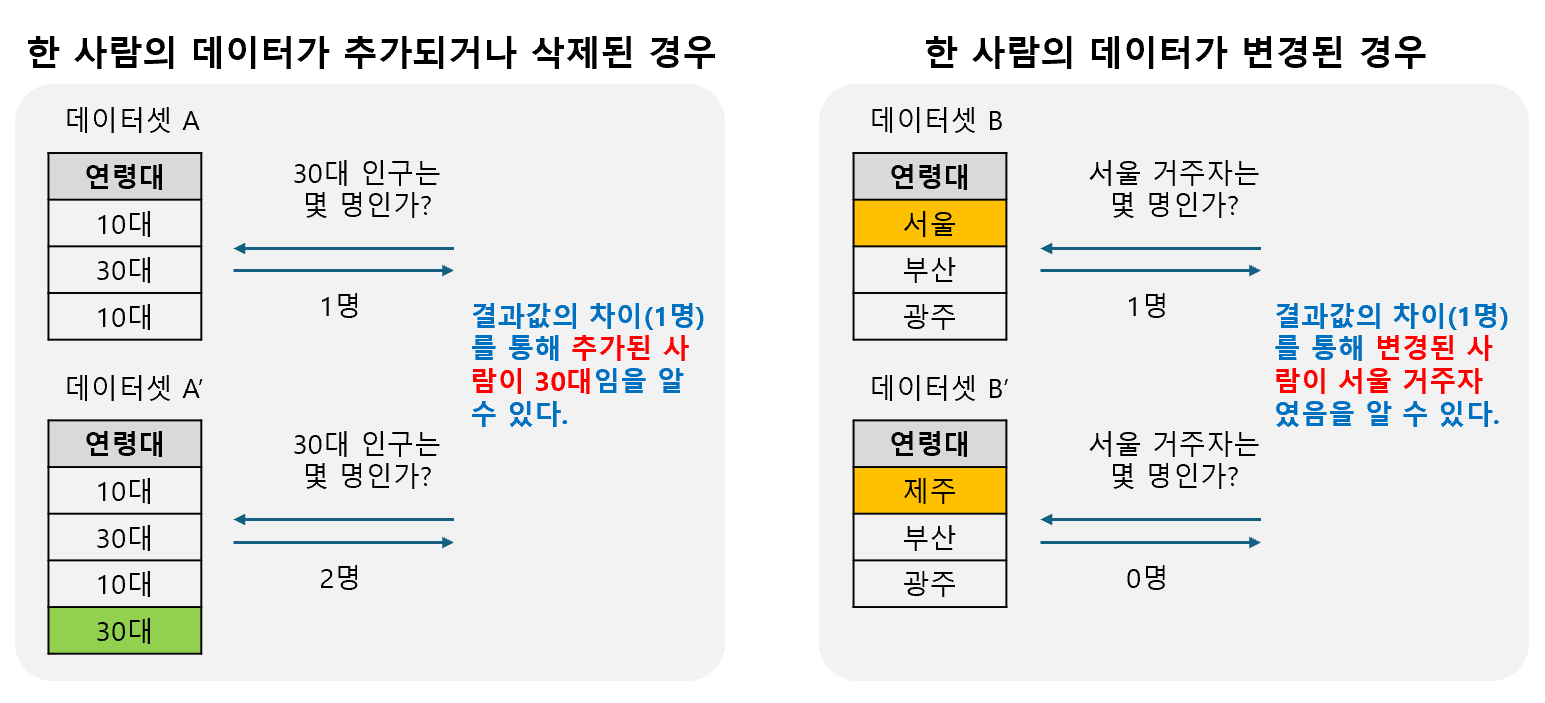
익명화(Anonymization)는 개인 식별 정보를 제거하거나 변환하여 데이터의 유용성은 유지하면서 개인정보를 안전하게 보호하는 핵심 기술입니다. 본 문서는 성공적인 데이터 익명화를 위해 '왜' 익명화가 필요한지 이해하고, 보호 수준을 측정하는 '무엇(프라이버시 모델)'을 배우며, 이를 구현하는 '어떻게(처리 기법)'를 단계적으로 알아봅니다.1. 주요 용어 정리익명화 기법을 이해하기 전에 몇 가지 핵심 용어를 알아두는 것이 좋습니다.식별자 (Identifier): 그 자체만으로 특정 개인을 바로 알아볼 수 있는 정보입니다. (예: 주민등록번호, 여권번호, 이름, 전화번호)준식별자 (Quasi-identifier): 단독으로는 개인을 식별하기 어렵지만, 다른 정보와 결합하면 특정 개인을 추론할 수 있는 ..