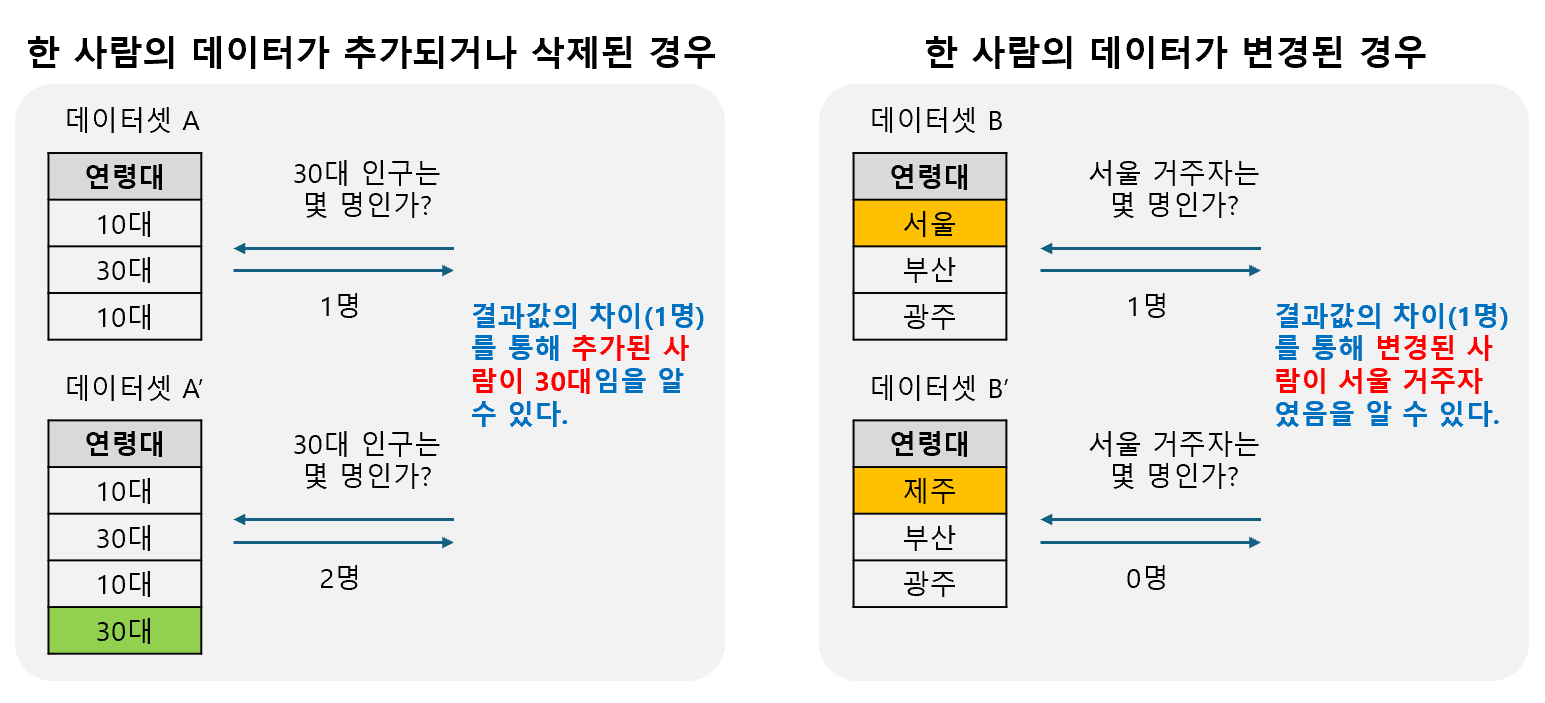
데이터 처리 방식에 따른 분류데이터에 직접 적용되어 프라이버시를 보장하는 핵심 알고리즘들입니다.노이즈 추가차등 정보보호에서 가장 보편적으로 사용되는 기법입니다. 핵심 원리는 데이터베이스에 대한 통계적 질의(Query)의 결과값에 수학적으로 생성된 '노이즈(noise)'라고 불리는 무작위 숫자를 더하여, 개별 데이터의 기여도를 모호하게 만드는 것입니다.작동 원리쿼리 실행: 데이터 분석가가 데이터베이스에 쿼리(예: "30대 사용자들의 평균 소득은 얼마인가?")를 실행하면, 시스템은 먼저 실제 결과값을 계산합니다.민감도(Sensitivity) 계산: 쿼리 결과가 데이터베이스 내의 단 한 사람의 데이터 변화에 의해 얼마나 크게 변할 수 있는지를 측정합니다. 예를 들어, 한 사람의 데이터를 추가하거나 제거했을 때..